My name is Ivan, and I've been doing SEO, full-time, since 2015.
I offer a variety of DFW SEO services and consultancy options, but my specialty is off-page link-building and ORM SEO.
DFW is an acronym for the Dallas-Fort Worth Metropolitan Area of Texas, which is where I live, and operate my SEO Consultancy.
Please read about my package offerings, below, and if it sounds good to you, then contact me, and we can get started.
COST: $125/once + $375/mo, per KW/PG for +10RD/mo.
AVERAGE: 1-keyword, 1-page, 30 Referring Domains/mo.
($1,125/mo)
TIME TO RANK: 1yr+, from new page.
SEO is an acronym, which means "Search Engine Optimization".
The purpose of SEO is to rank web pages higher in search engines, like Google or YouTube, so that they can get a larger share of traffic from people who are typing-in various queries.
So, if you have a business involved in selling a particular product or service, and you know your customers are using certain phrases to shop for those things, then you can optimize your business web pages, so that you are one of the first results to be seen for those queries, and subsequently, that is likely to result in more traffic and sales for your business.

This is accomplished by having the right terms on your web pages, and by receiving quality backlinks from other websites to those pages, which confirms your content's relevance.
In short, SEO is basically your content being linked-to by both internal and external content.
SEO Consultants, companies, and agencies can charge a widely varying range of prices, depending on the factors they have set for their operational infrastructure.
In a broad sense, many companies tend to charge in the low-to-mid thousands per month, on average, but it depends on how they do things, and how much competition there is for your target queries.
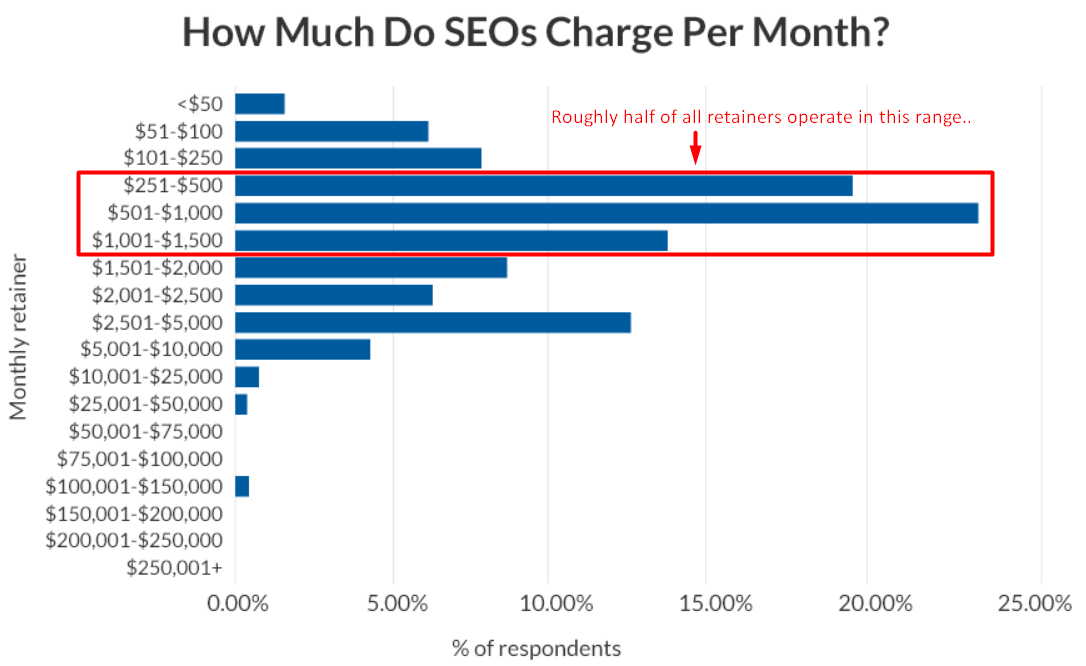
For me, I charge one-off prices for simple consulting services, and that is mainly based on how much time it takes me to fulfill those specific tasks.
Other than that, the main power of what I offer is the ability to identify, and acquire, quality backlinks, from a wide-range of referring domains.
In my experience, and observation, it is best to acquire as many quality referring domains as possible, so that your link profile is highly diversified.
As such, I charge a retainer for monthly link-building, and it's based on either the quantity of keywords or pages you want to rank for, which keeps your budget focused, and scalable.
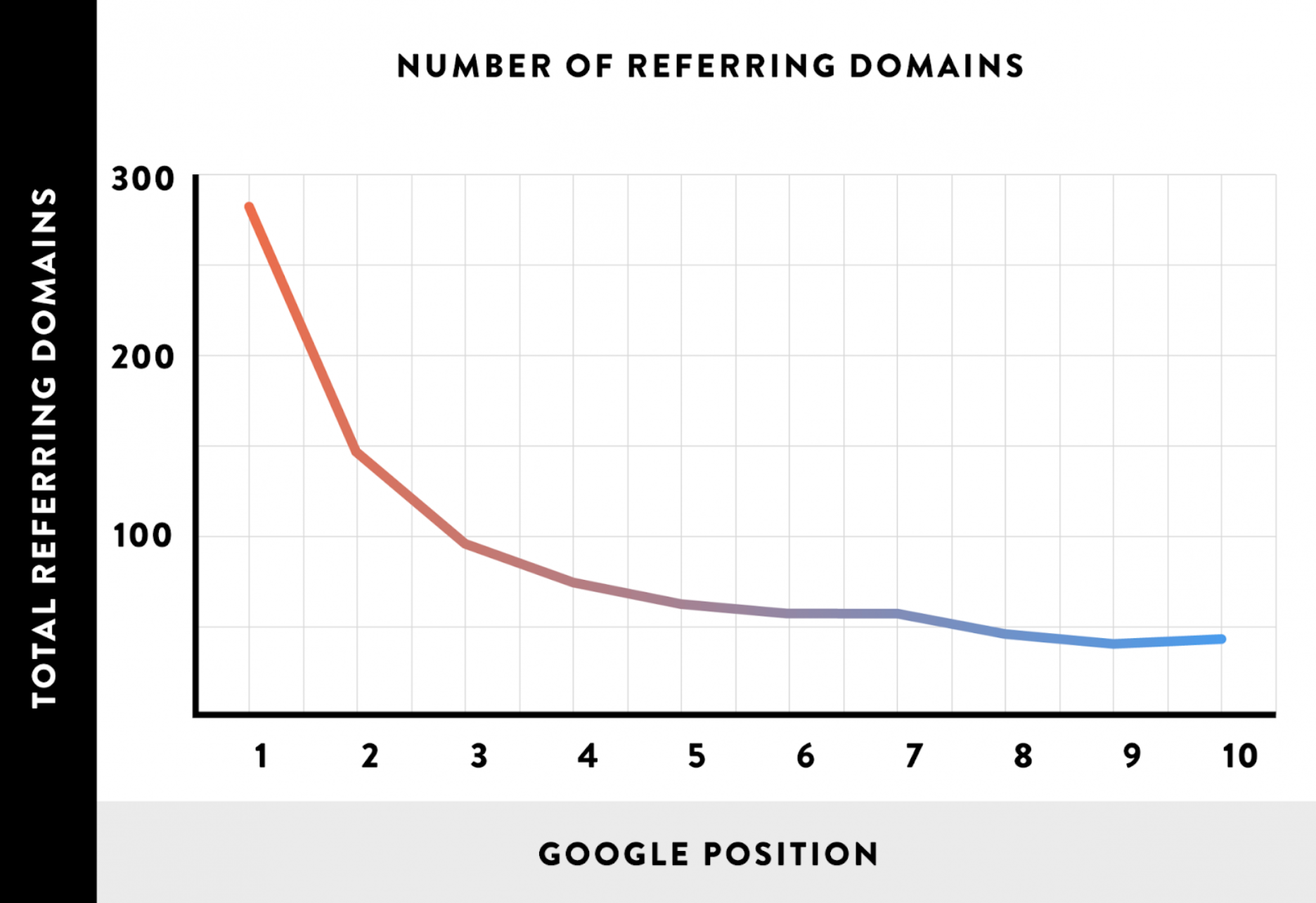
Statistically speaking, it takes 50 to 300 referring domains to reach the first page of a query, depending on competition.
In mega competitive SERPs, it may take more, and this is why it is recommended to include an SEO Audit with retainers.
My base link-building package generates an average of 120 tiered referring domains per year, to a single web page.
Along the way to achieving your ranking goals, it is common to rank for lesser longtail terms, or to be rotated by Google's algorithm, so increasing referring domains will tend to also result in progressively increasing organic traffic, along the way.
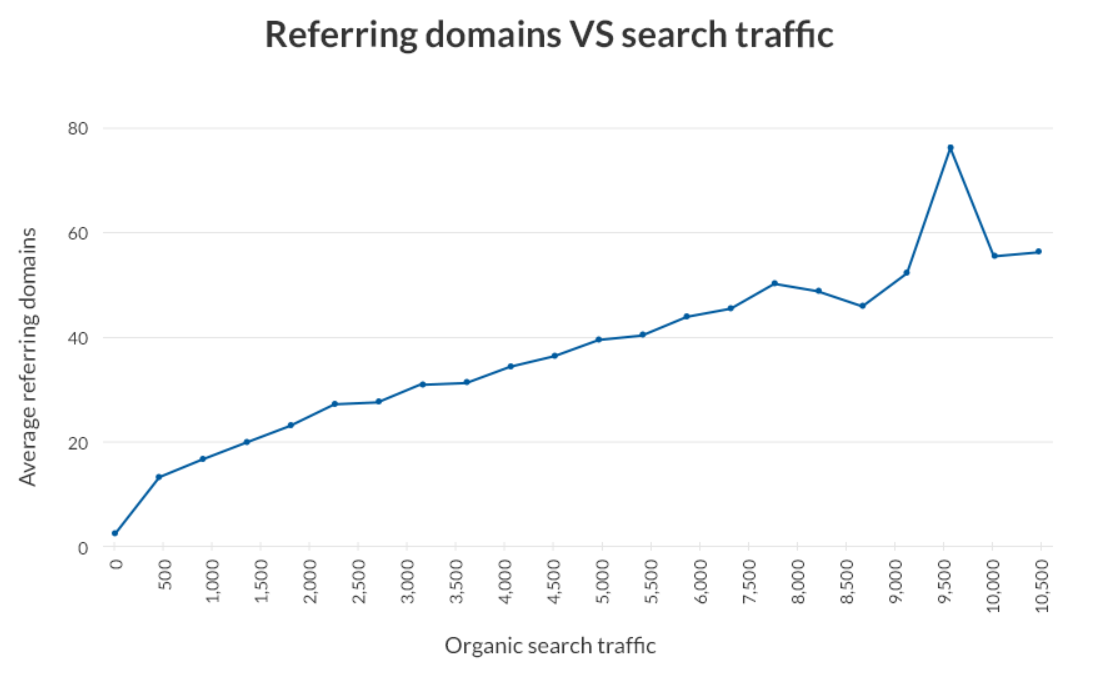
After one year, a particular page or keyword has a pretty good statistical chance to rank for your search term.
The more quantities you order, of my base package, the more referring domains you get each month, which means a high quality, more prolific, link profile for your properties.
Think of SEO Links as Digital Asset Real Estate.
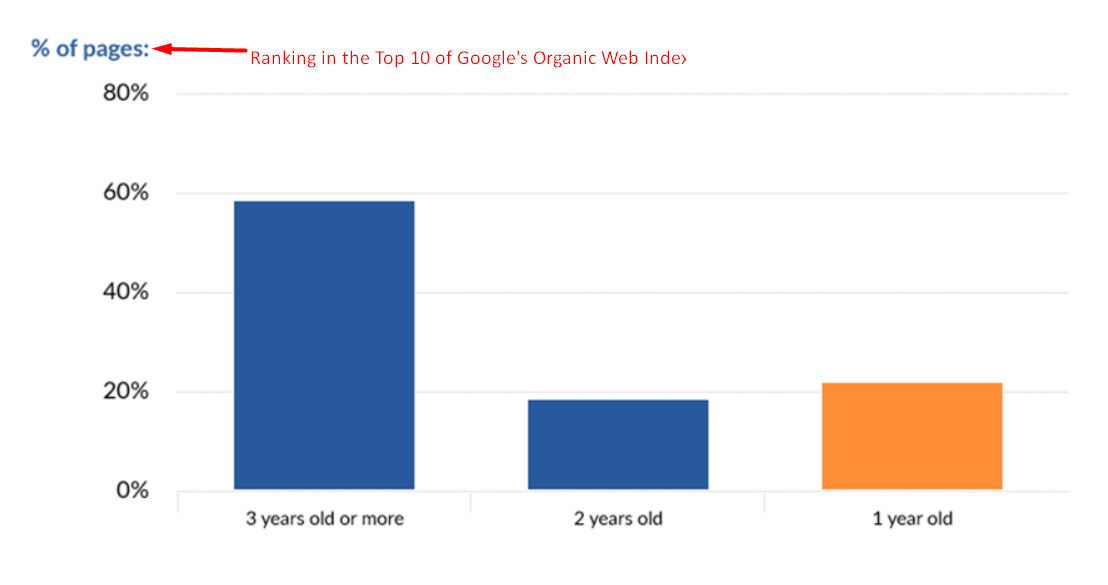
Statistically speaking, half of the web pages, out-there, take 1yr to 2yrs to rank in the Top 10, and the other half can take 3yrs+.
So, it takes 1yr to 3yrs, or more, to Rank in Google for competitive keywords, unless you have pre-existing rankings.
If you are already close to ranking for something, then it can be much faster, but when it comes to SEO, I always encourage my customers to budget for at-least 1yr, and refer to their project SERP tracker, each month, so they can measure their progress.

As the saying goes, you can get good, cheap, or fast SEO, but you can only pick two of the three, and I think that's true.
I could spend an hour describing the pros and cons of each dichotomy, but to summarize, my service goes for "good" and "cheap", but it's NOT "fast".
This is the best combination, I would argue, because most businesses cannot afford the cost of speed, and the ROI generally would not justify it for many years, even if they could.
If you go too fast, without investing in really strong links, then it also looks very suspicious to Google, as well.
So, it's best to start with small link quantities, go slow, and ramp-up over the course of a year.
This is the safest, most effective, and most ROI practical approach for any SEO Service.
Calculating ROI, for your SEO efforts, is databased guesswork.
We can use several datapoints, just to figure-out if it's even worthwhile, but even so, you won't really know the actual ROI, until you have the rankings to show for it.
In my experience, the results have always been more profitable than expected, because you will tend to rank for longtail keywords things along the way.
I can't guarantee that will always be the case, though, especially since niches vary, and products and services vary, and ultimately there could be many other variables.
All that aside, though, just based on some of these web-wide averages, and the prices I charge, let's consider the data.
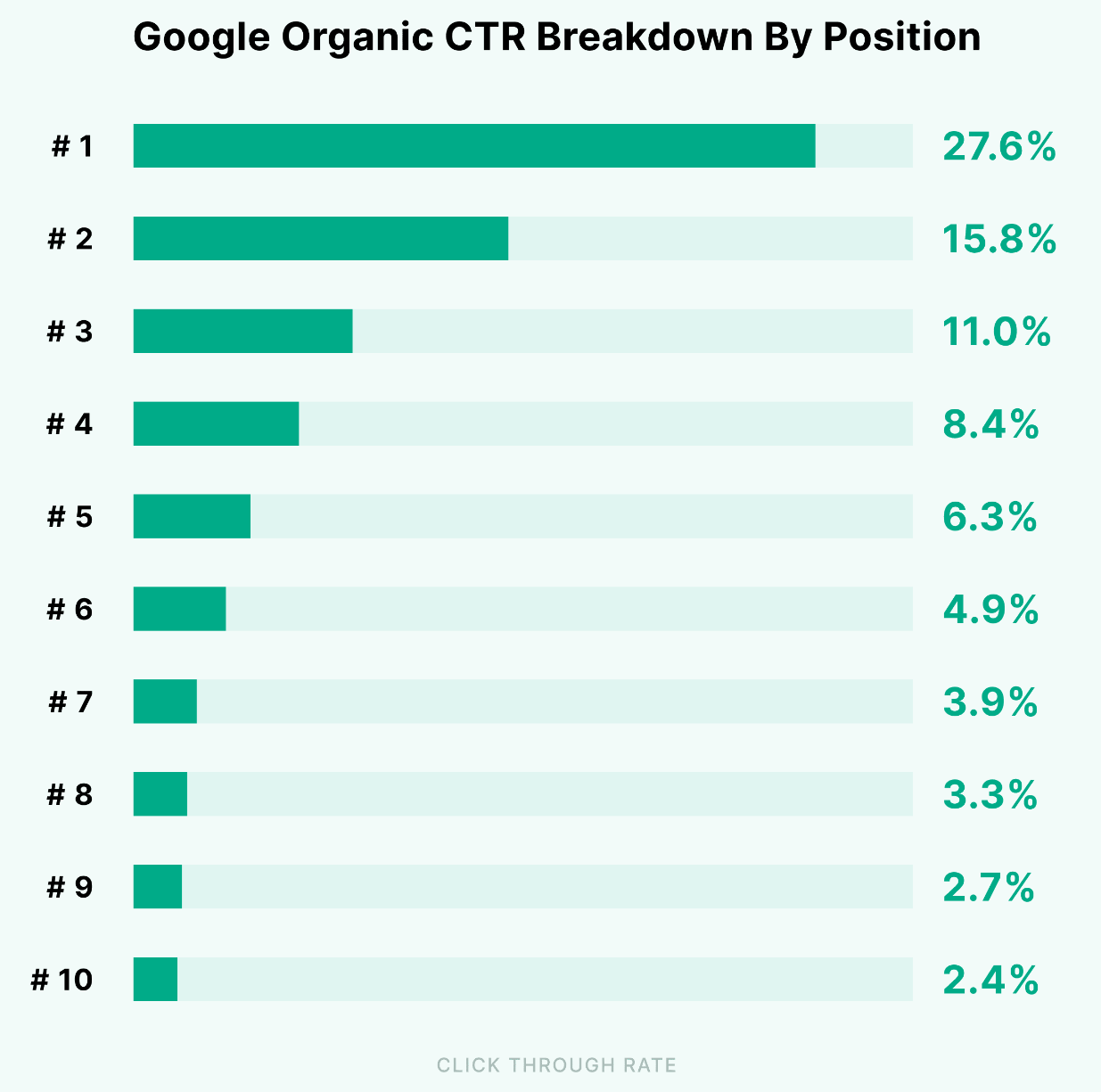
According to large-scale data, roughly half of all clicks in the SERPs are going to the first three ranking positions.
The other half go to positions four to ten, and there is also a bit that goes to page-2, contrary to popular belief.
The goal of my base package is to get a webpage at-least in the middle of the first page of the SERPs, for its query.
So, that's about a 5% clickthrough rate, which of-course can be improved significantly, as your position increases up-to #1.
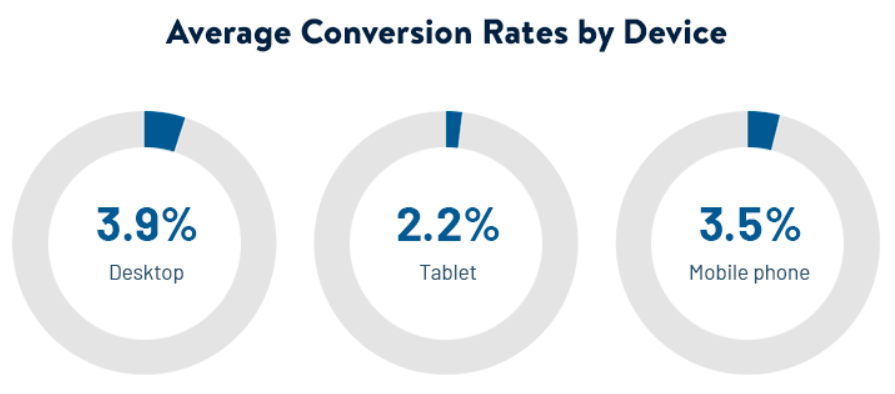
Conversion rate data can vary widely, depending on your niche, product, CTA, etc, but most large-scale aggregations put industry-wide conversions at about 3%, on average.
A lot of variables can increase that number, of course, like closing your sales over the phone, for example, but for the sake of being reasonably conservative, I think that's a good standard.
So, if we target a keyword with 670 impressions, per month, with a CTR of 5%, that's about 34-Clickthroughs, and with a 3% conversion rate, that's about 1-sale per month.
That means your product or service has to justify the cost of the retainer, probably for a year or more, and then your increased sales have to have the ability to be profitable on top of the SEO Retainer you are paying each month.
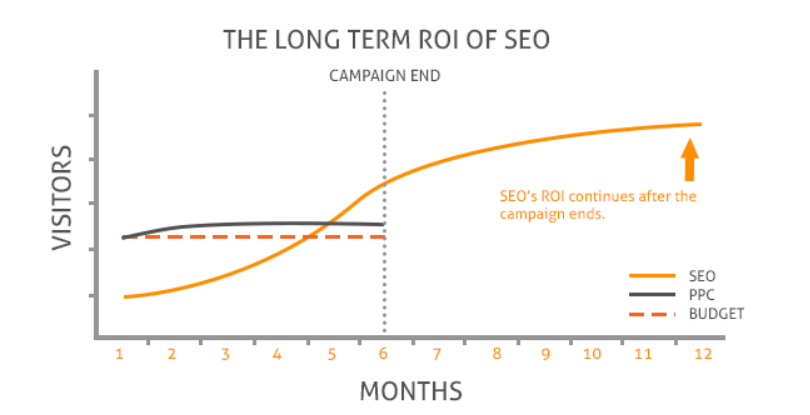
The great thing about SEO, of course, is that even after you stop paying, you still have assets that bring you more and more traffic each month, which is one reason why it has the highest average ROI of any marketing method.
What you wanna do, though, is pivot your budget to other terms or pages, which adds more streams of recurring revenue.
In that way, SEO is retroactive, which makes it unique.

Most other marketing methods trade some finite amount of cash for a temporary benefit of traffic, but with SEO, it's like rolling a snowball down a hill... it just keeps getting bigger and bigger.
The sooner you start, the better, because SEO is like compounding interest for inbound marketing.
For all projects, my clients receive a LIVE URL, which updates the search engine ranking positions (SERPs) on a regular basis.
I do not send manual reports and updates to clients, or deliverable samples, the results are automatically tracked by their SERP tracking dashboard, each month, and their page links can be checked with free tools, periodically.
Loan SEO Case StudyAbove, is a screenshot, and LIVE SERP link, from a 90-day viewable on a 2yr regular affiliate SEO project with very high competition in "loan" niches.
This private project had a budget of less than $100/mo, and in its last two months, I started ramping-up the link-building, which clearly began to generate more rapid ranking progress.
Its current number of referring domains is comparable to 1yr of my base SEO package retainer.
Below, you will find a similar screenshot, and LIVE SERP view, for one of my most successful ORM SEO projects, so far.
This is also a 2yr+ project, but with a much lower budget than would be typical for Online Reputation Management.
A normal retainer would be $3,375k+/mo, at the base, but this project was executed, VERY slowly, at $750/mo, and it has still been successful at acquiring rankings to surpass bad entities.
Even though specifics are redacted, if you click the keyword on the SERP viewable, at the bottom, you can see detailed SERP tracking on a 90-day period.
When this project began, we had a couple tough entities at the top, right below the brand website, and now we have several entities above the bad sites, with the overall goal being to fully suppress the evil sites from the first page. Y-NV ORM SEO Case Study
No matter your project type, you will get your own LIVE SERP tracking dashboard link, which you can access anytime.
It comes with a variety of viewables, download features, search and filtering features, and it updates daily, so there is a hard history of longterm SERP movement for your project.
For both ORM, and regular SEO, viewables, the position tracking is awesome for me, as well, because it lets me see what is closest to ranking, for maybe what ranked for a short period of time, and that gives me great data for the next links to build.
If you are in the early stages of developing your business' SEO strategy, I can help you with keyword research and SEO audits, which will give you data on hard numbers of referring domains, that you need to achieve, in order to get your pages ranked alongside competitors.
Once you know what to keywords build towards, then you will need to develop SEO on-page optimized web pages, which are crafted to rank for specific terms your customers are searching for in Google.
This is the foundation of SEO, and you need at-least one page prepared, in order to be eligible for on-going SEO services.
COST: $125/hr, for Consult and Screen Recording.
AVERAGE: 1hr.
DELIVERY: 1-day, or less.
Once you have a page that is prepared to rank for a keyword, then it is eligible for monthly SEO link-building services.
This is my specialty, and my mechanism of-choice for SEO.
Unlike other competitors, whose focus is in on-page or blogging, I actually know how to find quality backlinks, and how to build the kind of diversified link profile that Google likes to see.
My goal is to acquire large numbers of referring domains, from sites that have SERP verifiable keyword rankings.
My goal is to acquire links from websites that Google respects enough to rank, and if they are ranking, then there is a higher likelihood that those kinds of backlinks will be looked on more favorably by Google.
It is my job to find those kinds of links for your budget.
Using this strategy, over time, with enough referring domains, you will watch your keyword rankings steadily increase.
COST: $375/mo per KW/PG for +10RD/mo.
AVERAGE: 1-keyword, 1-page, 30 Referring Domains/mo.
($1,125/mo)
TIME TO RANK: 1yr, from new page.
ORM is a specialized field of SEO, which, from what I can tell, is the most difficult subset of search engine optimization to implement.
The idea, here, is you've got a keyword where you have multiple pages, and you need to rank those listings above malicious entities.
Usually, these malicious entities would be bad review pages, ugly news stories, or other skewed propaganda.
Beneficial brand entities tend to be social media pages, good reviews, and press releases.
I have some noteworthy experience, and success, providing reputation management services.
COST: $375/mo, per KW/PG for +10RD/mo.
AVERAGE: 1-keyword, 9-pages, 10 Referring Domains/mo
($3,375/mo)
TIME TO RANK: 1yr, from new page.
Information we collect
Log data:
When you visit our website, our servers may automatically log the standard data provided by your web browser.
It may include your computer’s Internet Protocol (IP) address, your browser type and version, the pages you visit, the time and date of your visit, the time spent on each page, and other details.
Device data:
We may also collect data about the device you’re using to access our website.
This data may include the device type, operating system, unique device identifiers, device settings, and geo-location data.
What we collect can depend on the individual settings of your device and software.
We recommend checking the policies of your device manufacturer or software provider to learn what information they make available to us.
Personal information:
We may ask for personal information, such as your:
NameEmailSocial media profilesDate of birthPhone/mobile numberHome/Mailing addressWork addressPayment information
Legal basis for processing
We will process your personal information lawfully, fairly, and in a transparent manner.
We collect and process information about you only where we have legal bases for doing so.These legal bases depend on the services you use and how you use them, meaning we collect and use your information only where:it’s necessary for the performance of a contract to which you are a party or to take steps at your request before entering into such a contract (for example, when we provide a service you request from us);
it satisfies a legitimate interest (which is not overridden by your data protection interests), such as for research and development, to market and promote our services, and to protect our legal rights and interests;
you give us consent to do so for a specific purpose (for example, you might consent to us sending you our newsletter); or
we need to process your data to comply with a legal obligation.Where you consent to our use of information about you for a specific purpose, you have the right to change your mind at any time (but this will not affect any processing that has already taken place).We don’t keep personal information for longer than is necessary.
While we retain this information, we will protect it within commercially acceptable means to prevent loss and theft, as well as unauthorized access, disclosure, copying, use or modification.
That said, we advise that no method of electronic transmission or storage is 100% secure and cannot guarantee absolute data security. If necessary, we may retain your personal information for our compliance with a legal obligation or in order to protect your vital interests or the vital interests of another natural person.
Collection and use of information
We may collect, hold, use and disclose information for the following purposes and personal information will not be further processed in a manner that is incompatible with these purposes:— to enable you to customise or personalise your experience of our website; to enable you to access and use our website, associated applications and associated social media platforms; to contact and communicate with you; for internal record keeping and administrative purposes; for analytics, market research and business development, including to operate and improve our website, associated applications and associated social media platforms; to run competitions and/or offer additional benefits to you; for advertising and marketing, including to send you promotional information about our products and services and information about third parties that we consider may be of interest to you; to comply with our legal obligations and resolve any disputes that we may have; and to consider your employment application.
Disclosure of personal information to third parties
We may disclose personal information to:— third party service providers for the purpose of enabling them to provide their services, including (without limitation) IT service providers, data storage, web-hosting and server providers, debt collectors, maintenance or problem-solving providers, marketing or advertising providers, professional advisors and payment systems operators; our employees, contractors and/or related entities; sponsors or promoters of any competition we run; credit reporting agencies, courts, tribunals and regulatory authorities, in the event you fail to pay for goods or services we have provided to you; courts, tribunals, regulatory authorities and law enforcement officers, as required by law, in connection with any actual or prospective legal proceedings, or in order to establish, exercise or defend our legal rights;third parties, including agents or sub-contractors, who assist us in providing information, products, services or direct marketing to you; and third parties to collect and process data.
International transfers of personal information
The personal information we collect is stored and processed in United States, or where we or our partners, affiliates and third-party providers maintain facilities.
By providing us with your personal information, you consent to the disclosure to these overseas third parties.We will ensure that any transfer of personal information from countries in the European Economic Area (EEA) to countries outside the EEA will be protected by appropriate safeguards, for example by using standard data protection clauses approved by the European Commission, or the use of binding corporate rules or other legally accepted means.Where we transfer personal information from a non-EEA country to another country, you acknowledge that third parties in other jurisdictions may not be subject to similar data protection laws to the ones in our jurisdiction.
There are risks if any such third party engages in any act or practice that would contravene the data privacy laws in our jurisdiction and this might mean that you will not be able to seek redress under our jurisdiction’s privacy laws.
Your rights and controlling your personal information
Choice and consent:
By providing personal information to us, you consent to us collecting, holding, using and disclosing your personal information in accordance with this privacy policy.
If you are under 16 years of age, you must have, and warrant to the extent permitted by law to us, that you have your parent or legal guardian’s permission to access and use the website and they (your parents or guardian) have consented to you providing us with your personal information.
You do not have to provide personal information to us, however, if you do not, it may affect your use of this website or the products and/or services offered on or through it.
Information from third parties:
If we receive personal information about you from a third party, we will protect it as set out in this privacy policy.
If you are a third party providing personal information about somebody else, you represent and warrant that you have such person’s consent to provide the personal information to us.
Restrict:
You may choose to restrict the collection or use of your personal information.
If you have previously agreed to us using your personal information for direct marketing purposes, you may change your mind at any time by contacting us using the details below.
If you ask us to restrict or limit how we process your personal information, we will let you know how the restriction affects your use of our website or products and services.
Access and data portability:
You may request details of the personal information that we hold about you.
You may request a copy of the personal information we hold about you.
Where possible, we will provide this information in CSV format or other easily readable machine format.
You may request that we erase the personal information we hold about you at any time.
You may also request that we transfer this personal information to another third party.
Correction:
If you believe that any information we hold about you is inaccurate, out of date, incomplete, irrelevant or misleading, please contact us using the details below.
We will take reasonable steps to correct any information found to be inaccurate, incomplete, misleading or out of date.
Notification of data breaches:
We will comply laws applicable to us in respect of any data breach.
Complaints:
If you believe that we have breached a relevant data protection law and wish to make a complaint, please contact us using the details below and provide us with full details of the alleged breach.
We will promptly investigate your complaint and respond to you, in writing, setting out the outcome of our investigation and the steps we will take to deal with your complaint.
You also have the right to contact a regulatory body or data protection authority in relation to your complaint.
Unsubscribe:
To unsubscribe from our e-mail database or opt-out of communications (including marketing communications), please contact us using the details below or opt-out using the opt-out facilities provided in the communication.
Business transfers
If we or our assets are acquired, or in the unlikely event that we go out of business or enter bankruptcy, we would include data among the assets transferred to any parties who acquire us.
You acknowledge that such transfers may occur, and that any parties who acquire us may continue to use your personal information according to this policy.
Cookie Policy
We use cookies to help improve your experience of this website. This cookie policy is part of this website’s privacy policy, and covers the use of cookies between your device and our site. We also provide basic information on third-party services we may use, who may also use cookies as part of their service, though they are not covered by our policy.If you don’t wish to accept cookies from us, you should instruct your browser to refuse cookies from this website, with the understanding that we may be unable to provide you with some of your desired content and services.
What is a cookie?
A cookie is a small piece of data that a website stores on your device when you visit, typically containing information about the website itself, a unique identifier that allows the site to recognise your web browser when you return, additional data that serves the purpose of the cookie, and the lifespan of the cookie itself.Cookies are used to enable certain features (eg. logging in), to track site usage (eg. analytics), to store your user settings (eg. timezone, notification preferences), and to personalise your content (eg. advertising, language).Cookies set by the website you are visiting are normally referred to as “first-party cookies”, and typically only track your activity on that particular site. Cookies set by other sites and companies (ie. third parties) are called “third-party cookies”, and can be used to track you on other websites that use the same third-party service.
Essential cookies
Essential cookies are crucial to your experience of a website, enabling core features like user logins, account management, shopping carts and payment processing. We use essential cookies to enable certain functions on our website.
Performance cookies
Performance cookies are used in the tracking of how you use a website during your visit, without collecting personal information about you. Typically, this information is anonymous and aggregated with information tracked across all site users, to help companies understand visitor usage patterns, identify and diagnose problems or errors their users may encounter, and make better strategic decisions in improving their audience’s overall website experience. These cookies may be set by the website you’re visiting (first-party) or by third-party services. We use performance cookies on our site.
Functionality cookies
Functionality cookies are used in collecting information about your device and any settings you may configure on the website you’re visiting (like language and timezone settings). With this information, websites can provide you with customised, enhanced or optimised content and services. These cookies may be set by the website you’re visiting (first-party) or by third-party service. We use functionality cookies for selected features on our site.
Targeting/advertising cookies
Targeting/advertising cookies are used in determining what promotional content is more relevant and appropriate to you and your interests. Websites may use them to deliver targeted advertising or to limit the number of times you see an advertisement. This helps companies improve the effectiveness of their campaigns and the quality of content presented to you. These cookies may be set by the website you’re visiting (first-party) or by third-party services. Targeting/advertising cookies set by third-parties may be used to track you on other websites that use the same third-party service. We use targeting/advertising cookies on our site.
Third-party cookies on our site
We may employ third-party companies and individuals on our websites—for example, analytics providers and content partners. We grant these third parties access to selected information to perform specific tasks on our behalf. They may also set third-party cookies in order to deliver the services they are providing. Third-party cookies can be used to track you on other websites that use the same third-party service. As we have no control over third-party cookies, they are not covered by this website’s cookie policy.
Our third-party privacy promise
We review the privacy policies of all our third-party providers before enlisting their services to ensure their practices align with ours. We will never knowingly include third-party services that compromise or violate the privacy of our users.
How you can control or opt out of cookies
If you do not wish to accept cookies from us, you can instruct your browser to refuse cookies from our website. Most browsers are configured to accept cookies by default, but you can update these settings to either refuse cookies altogether, or to notify you when a website is trying to set or update a cookie.If you browse websites from multiple devices, you may need to update your settings on each individual device.Although some cookies can be blocked with little impact on your experience of a website, blocking all cookies may mean you are unable to access certain features and content across the sites you visit.
Terms of Service
By accessing this website, and using its parent company products, services, and content, you are agreeing to be bound by these terms of service, all applicable laws and regulations, and agree that you are responsible for compliance with any applicable local laws. If you do not agree with any of these terms, you are prohibited from using or accessing this site.
The materials contained in this website are protected by applicable copyright and trademark law.
Use License
Permission is granted to temporarily download one copy of the materials (information or software) on this website for personal, non-commercial transitory viewing only.
This is the grant of a license, not a transfer of title, and under this license you may not: modify or copy the materials; use the materials for any commercial purpose, or for any public display (commercial or non-commercial);attempt to decompile or reverse engineer any software contained on this website;remove any copyright or other proprietary notations from the materials; ortransfer the materials to another person or “mirror” the materials on any other server. This license shall automatically terminate if you violate any of these restrictions and may be terminated by this at any time.
Upon terminating your viewing of these materials or upon the termination of this license, you must destroy any downloaded materials in your possession whether in electronic or printed format.
Service Disclaimer
The materials on this website are provided on an ‘as is’ basis. This site makes no warranties, expressed or implied, and hereby disclaims and negates all other warranties including, without limitation, implied warranties or conditions of merchantability, fitness for a particular purpose, or non-infringement of intellectual property or other violation of rights. Further, this website does not warrant or make any representations concerning the accuracy, likely results, or reliability of the use of the materials on its website, the services provided, or otherwise relating to such materials or services on any sites linked to this site.
Risks and Limitations of Service
In no event shall this website or its suppliers be liable for any damages (including, without limitation, damages for loss of data or profit, or due to business interruption) arising out of the use or inability to use the materials on this website, or from its products or services, even if this website or an authorized representative of this website, has been notified orally or in writing of the possibility of such damage.
Because some jurisdictions do not allow limitations on implied warranties, or limitations of liability for consequential or incidental damages, some facets of these limitations may not apply to you, with exception to purchases of products or services.
Due to the nature of SEO Services and Consultancy, while each section of this website endeavors to demonstrate large-scale statistical likelihood of results, given the fact that the owner's of this website are not fully in-control of Google's Search Results, we cannot guarantee any outcome or specific results of any kind.
By purchasing SEO products, services, or consultancy, from this website or its operators, you agree that you have read and reviewed the descriptions of these services, in-full, understanding the risks and uncertain nature of Search Engine Optimization, and assume full responsibility for any subsequently undesirable results.
For all Link-Building Services purchased, you agree to an understanding of the risks involved, and waive this website, with its owners and operators, from any liability in the implementation or consequences of its services.
Accuracy of materials
The materials appearing on this website could include technical, typographical, or photographic errors.
This website does not warrant that any of the materials on its website are accurate, complete or current. This website may make changes to the materials contained on its website at any time without notice.
However, this website does not make any commitment to update the materials.
Links
This website has not reviewed all of the sites linked to its website and is not responsible for the contents of any such linked site.
The inclusion of any link does not imply endorsement by this website of the site linked.
Use of any such linked website is at the user’s own risk.
Modifications
This website may revise these terms of service for its website at any time without notice.
By using this website you are agreeing to be bound by the then current version of these terms of service.
Governing Law
These terms and conditions are governed by and construed in accordance with the laws of Texas and you irrevocably submit to the exclusive jurisdiction of the courts in that State or location.
Refund Policy
Unless Otherwise Specified, on a per-product basis, our Blanket Refund Policy is Completely Discretionary.
Meaning that it is 100% up to the owners, of this website, whether or not a Refund is in-order, for any purchase whatsoever.
In most cases, a Refund is NOT possible, due to the nature of expended time for services, as well as certain operational costs associated with implementation.
By using this website, or making purchases through its service providers, you completely agree with the terms laid-out in this document, including all Refund Policies, as well as Risks and Service Limitations aforementioned.
Limits of our policies
Our website may link to external sites that are not operated by us.
Please be aware that we have no control over the content and policies of those sites, and cannot accept responsibility or liability for their respective privacy practices.
Changes to these policies
At our discretion, we may change our privacy policy to reflect current acceptable practices.
We may take reasonable steps to let users know about changes via our website.
Your continued use of this site, after any changes to this policy, will be regarded as acceptance of our policies and terms.
If we make a significant change to this privacy policy, for example changing a lawful basis on which we process your personal information, we may ask you to re-consent to the amended privacy policy.
Contact Methods may be found on our Homepage, or dedicated Contact Section, including forms or phone numbers.